 Z Lab
Z LabDFlash: Block Diffusion for Flash Speculative Decoding
Jian Chen, Yesheng Liang, Zhijian Liu
LLM inference is sequential: every token depends on the one before it. Speculative decoding tries to break this bottleneck: a small draft model proposes tokens, then the target LLM verifies them in parallel. But state-of-the-art methods like EAGLE-3 still draft autoregressively, capping practical speedups around 2-3×.
DFlash uses a lightweight block diffusion model to draft an entire block of tokens in a single parallel forward pass, achieving up to 6× lossless acceleration on Qwen3-8B, nearly 2.5× faster than EAGLE-3.
Quick Start
DFlash supports SGLang for production serving and Transformers for fast exploration. vLLM integration is in progress.
Installation
pip install "git+https://github.com/sgl-project/sglang.git@refs/pull/16818/head#subdirectory=python"Usage
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Coder-30B-A3B-Instruct \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3-Coder-30B-A3B-DFlash \
--tp-size 1 \
--dtype bfloat16 \
--attention-backend fa3 \
--mem-fraction-static 0.75 \
--trust-remote-codeInstallation
pip install transformers==4.57.3 torch==2.9.1 accelerateUsage
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
# 1. Load the DFlash Draft Model
model = AutoModel.from_pretrained(
"z-lab/Qwen3-8B-DFlash-b16",
trust_remote_code=True,
dtype="auto",
device_map="cuda:0"
).eval()
# 2. Load the Target Model
target = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-8B",
dtype="auto",
device_map="cuda:0"
).eval()
# 3. Load Tokenizer and Prepare Input
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
prompt = "How many positive whole-number divisors does 196 have?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. Run Speculative Decoding
generate_ids = model.spec_generate(
input_ids=model_inputs["input_ids"],
max_new_tokens=2048,
temperature=0.0,
target=target,
stop_token_ids=[tokenizer.eos_token_id]
)
print(tokenizer.decode(generate_ids[0], skip_special_tokens=True))Why DFlash?
Speculative decoding works by having a small draft model propose tokens that the large target LLM verifies in parallel. The bottleneck is the drafter: EAGLE-3, the current state of the art, drafts autoregressively, so it’s still sequential and caps out around 2-3× speedup.
Diffusion models can generate tokens in parallel, but using them as drafters isn’t straightforward. Methods like DiffuSpec and SpecDiff-2 use massive 7B-parameter drafters that are too expensive for real-world serving. And simply shrinking the diffusion model doesn’t work either:
| Greedy (temp=0) | GSM8K | Math500 | AIME24 | AIME25 |
|---|---|---|---|---|
| Acceptance length | 3.38 | 4.61 | 4.12 | 4.07 |
| Speedup | 2.83× | 3.73× | 3.43× | 3.35× |
| Sampling (temp=1) | GSM8K | Math500 | AIME24 | AIME25 |
|---|---|---|---|---|
| Acceptance length | 3.29 | 4.12 | 3.23 | 3.24 |
| Speedup | 2.76× | 3.31× | 2.66× | 2.65× |
Without access to the target model’s internal knowledge, the tiny drafter has to predict future tokens from scratch. Can we build a drafter that is both small and accurate?
How DFlash Works
The Key Insight: The Target Knows Best
A free lunch does exist. Large autoregressive LLMs’ hidden features implicitly contain information about multiple future tokens, a phenomenon also observed by Samragh et al.. Instead of asking a tiny diffusion model to reason from scratch, DFlash conditions the draft model on context features extracted from the target model, fusing the target’s deep reasoning with the drafter’s parallel speed.
Why Diffusion Changes the Game
There’s a deeper reason why diffusion drafting wins. Autoregressive drafters generate tokens one at a time, so drafting cost grows linearly with the number of tokens. This forces EAGLE-3 to use an extremely shallow architecture (a single transformer layer) to keep latency low, which severely limits draft quality.
Diffusion drafters generate all tokens in a single parallel forward pass, so drafting cost is essentially flat regardless of how many tokens you produce. This means DFlash can afford a much deeper, more expressive model without paying a latency penalty. In fact, a multi-layer DFlash generating 16 tokens has lower latency than a 1-layer EAGLE-3 generating 8 tokens. Deeper model, more tokens, less time.
Design
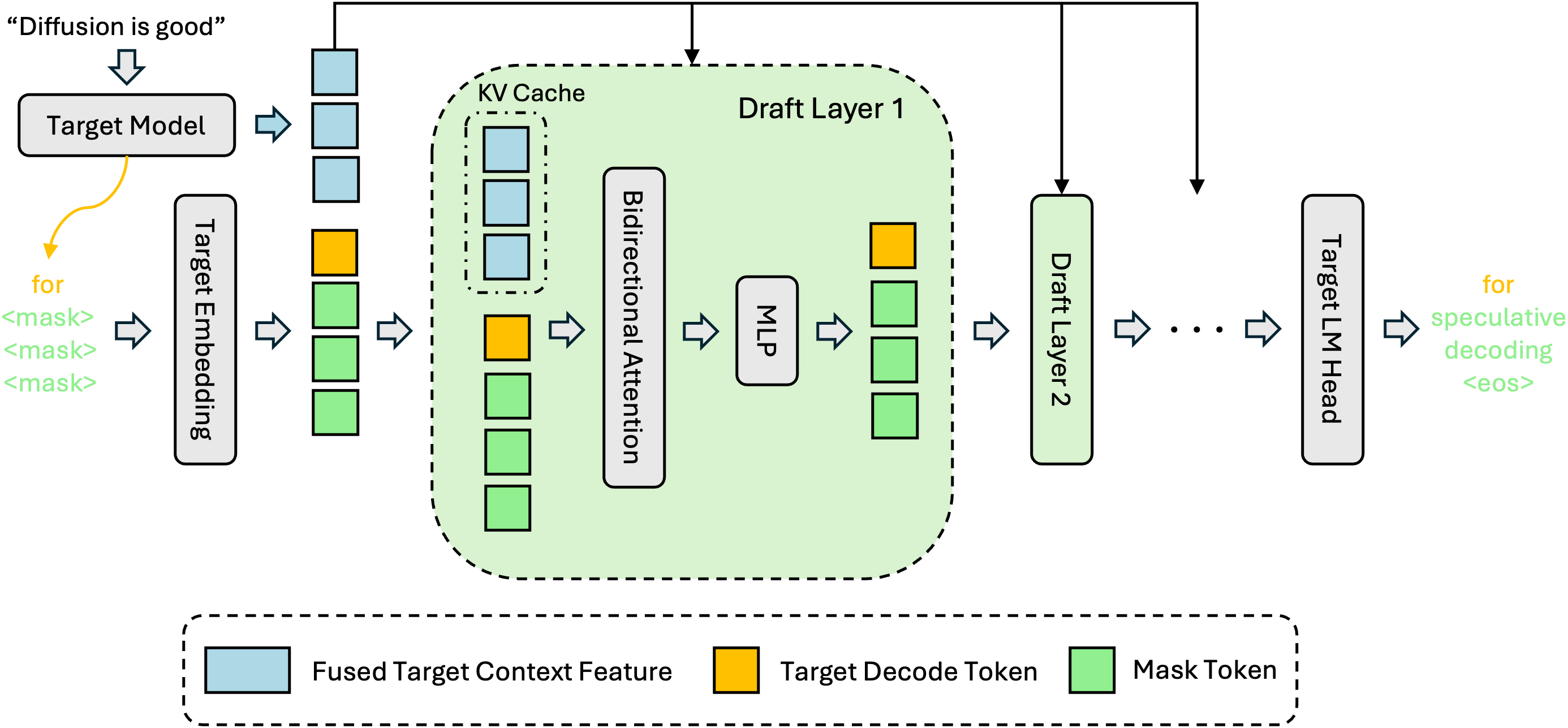
Feature Fusion: After prefill or verification, we extract hidden features from layers uniformly sampled across the target model and fuse them through a lightweight projection.
KV Injection: The fused features are injected directly into the Key/Value projections of every draft model layer and stored in the KV cache. This is a crucial difference from EAGLE-3, which feeds target features only as input to the first layer. In EAGLE-3, the signal dilutes as you add layers; in DFlash, every layer gets the full context, so acceptance length scales with depth.
Parallel Drafting: Conditioned on this rich context (and the last verified token), the drafter predicts the next block of tokens in a single forward pass using block diffusion.
The draft model reuses the embedding and LM head from the target model. Only the few intermediate layers are trained, keeping the parameter count minimal.
Results
We evaluate DFlash against EAGLE-3, the state-of-the-art speculative decoding method. DFlash uses block size 16 with a single denoising step. EAGLE-3 uses RedHatAI/Qwen3-8B-speculator.eagle3 with a speculation length of 7. See the GitHub repository to reproduce.
7 5.6 4.2 2.8 1.4 0 | ||||||||||
| GSM8K | MATH-500 | AIME24 | AIME25 | HumanEval | MBPP | LiveCodeBench | SWE-Bench | MT-Bench | Alpaca |
DFlash also maintains strong speedups under sampling (temperature=1) and with thinking mode enabled, achieving roughly 4.5× acceleration for reasoning models. Full results across Qwen3-4B, Qwen3-8B, Qwen3-Coder-30B-A3B, and LLaMA-3.1-8B are in the paper.
Conclusion
DFlash shows that diffusion models don’t need to compete with autoregressive LLMs in generation quality. They just need to be great drafters. By confining diffusion to the drafting stage and conditioning on target-model features, DFlash achieves both high acceptance rates and low drafting latency, pushing speculative decoding to over 6× lossless speedup.
This reframes the role of diffusion LLMs entirely. Instead of training massive dLLMs to match autoregressive quality, we can train lightweight diffusion adapters optimized for fast, accurate block prediction, with speculative verification guaranteeing output quality. DFlash is compatible with further dLLM acceleration techniques and supports production serving via SGLang.
Citation
@article{chen2026dflash,
title = {{DFlash: Block Diffusion for Flash Speculative Decoding}},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
journal = {arXiv preprint arXiv:2602.06036},
year = {2026}
}