 Z Lab
Z LabParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
Yesheng Liang, Haisheng Chen, Zihan Zhang, Song Han, Zhijian Liu
Reasoning LLMs think by generating tens of thousands of chain-of-thought tokens. Each token feeds back into the model to produce the next one, so quantization error doesn’t just appear once: it compounds at every step. With AWQ, the most popular INT4 method, 4-bit Qwen3-4B drops almost 3% on MMLU-Pro, and the degradation gets worse on harder benchmarks that require longer reasoning.
ParoQuant fixes this. With a novel, hardware-friendly transform called scaled pairwise rotation, ParoQuant achieves an average 2.4% accuracy improvement over AWQ on reasoning tasks, matching the accuracy of the best existing methods while running nearly as fast.
Quick Start
ParoQuant supports NVIDIA GPUs (via vLLM and Transformers) and Apple Silicon (via MLX):
pip install "paroquant[vllm]"
python -m paroquant.cli.chat --model z-lab/Qwen3.5-4B-PAROpip install "paroquant[mlx]"
python -m paroquant.cli.chat --model z-lab/Qwen3.5-4B-PAROdocker run --pull=always --rm -it --gpus all --ipc=host \
ghcr.io/z-lab/paroquant:chat --model z-lab/Qwen3.5-4B-PAROSee our Hugging Face collection for all supported models. ParoQuant also supports an OpenAI-compatible API server (paroquant.cli.serve) and a built-in agent with tool calling (paroquant.cli.agent). See the GitHub repo for details.
The Outlier Problem
Why does quantization hurt? LLM weights contain outlier channels: a handful of values with disproportionately large magnitudes that eat up the limited dynamic range of INT4, dragging down precision for everything else. The standard fix is to apply a mathematical transform to the weights before quantizing, smoothing out the outliers so the values become more “quantization-friendly.”
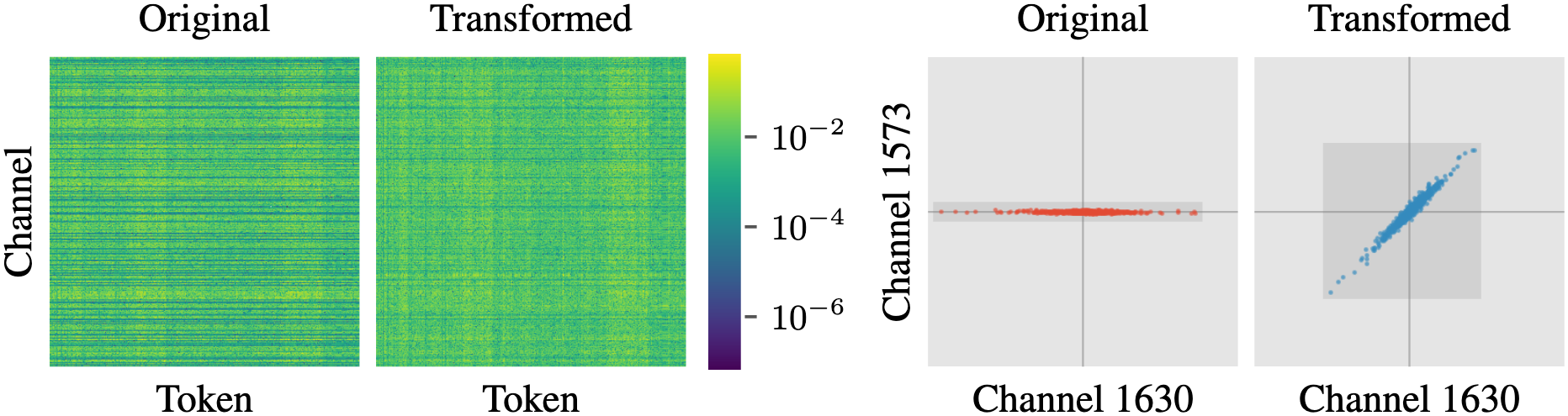
The catch is a fundamental trade-off. Existing transforms fall into one of two camps:
- Learnable but either expensive or restrictive. Full rotations and channel-wise scaling can adapt to each layer, but rotations require dense matrix multiplies that are too slow for online use, while channel-wise scaling lacks the expressiveness needed to effectively suppress outliers.
- Efficient but fixed. The Hadamard transform runs fast, but it’s the same for every layer, can’t adapt to the weight distribution, and still makes methods like QTIP about 30% slower than AWQ.
Can we design a transform that is learnable, expressive, and cheap enough to apply online?
Key Insight: 90% of Rotations Are Redundant
A full rotation is the gold standard for suppressing outliers, but it requires a dense matrix multiply, far too slow for online use. Is there a way to get the same effect for a fraction of the cost?
Any rotation matrix can be decomposed into a sequence of simple two-channel (Givens) rotations. Think of it this way: instead of rotating the entire space at once, you rotate one pair of channels at a time. Intuitively, not all pairs matter equally. Rotating an outlier channel with a normal channel does most of the heavy lifting; rotating two normal channels barely helps.
We validated this with a simple experiment: optimizing only the top 10% of pairs (selected by magnitude difference) matches the full rotation almost exactly:
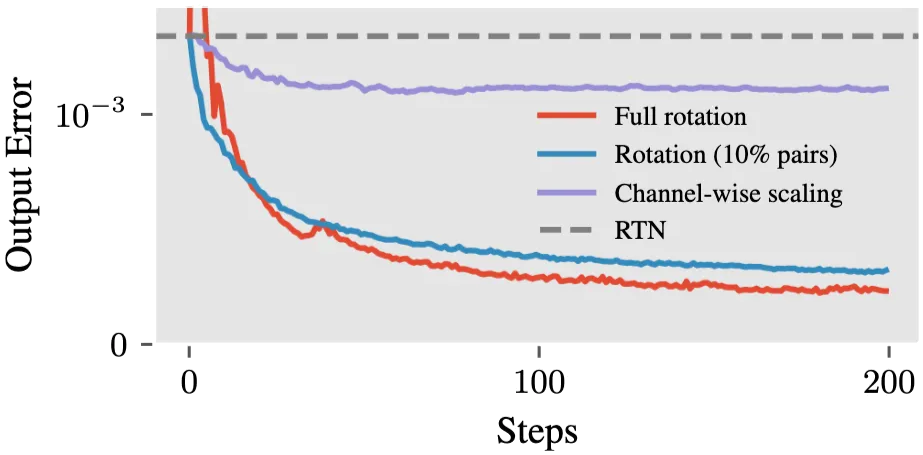
k_proj weight of LLaMA-3-8B. Keeping only the 10% of channel pairs with the largest magnitude difference (orange) matches a full rotation (blue), while channel-wise scaling alone (green) plateaus at a higher error.This is the key insight: full rotations are massively redundant. A small, carefully chosen subset of pairwise rotations is equally effective, and cheap enough to apply online.
Our Solution: Scaled Pairwise Rotation
Building on this insight, we propose the scaled pairwise rotation, constructed in three steps:
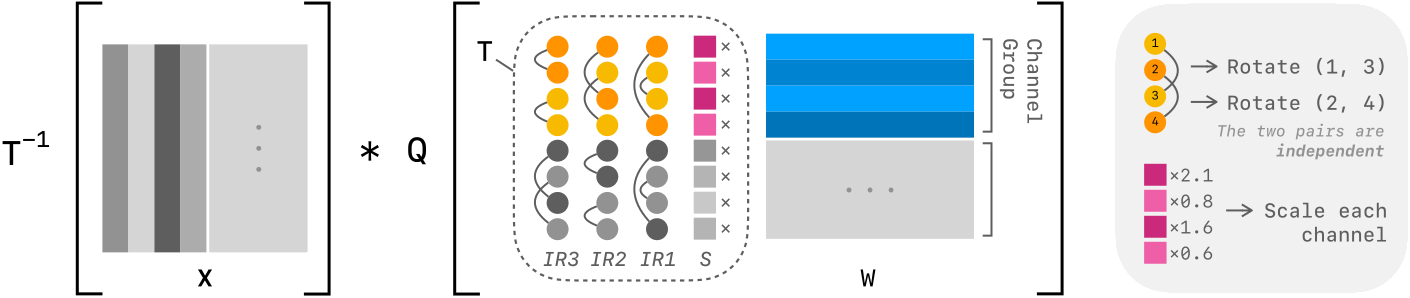
Replace the full rotation with a small set of pairwise (Givens) rotations. Each one is just a cheap two-channel operation.
Make all pairs independent so they can run fully in parallel on the GPU. We constrain each channel to appear in at most one pair, eliminating all dependencies between rotations. This is both an algorithmic and a system design choice: no dependencies means no synchronization, and every CUDA thread can work independently.
Stack multiple independent rotation sets and add channel-wise scaling. A single set of independent pairs is too limited on its own, but chaining several of them (we use 8) with per-channel scaling recovers the expressiveness of a full rotation. Interestingly, scaling and rotations are complementary: scaling evens out magnitudes across the entire matrix, while rotations align values within each channel pair. Neither alone is enough; together they match a full rotation.
The entire transform fits in a single fused CUDA kernel. Since each 128-channel group is small enough to live in shared memory, and the rotation parameters fit in registers, all 8 rotation rounds execute with a single memory load. The result: less than 10% overhead compared to AWQ. After applying scaled pairwise rotation, we further fine-tune the quantized weights to clean up any remaining rounding errors. For full details on the algorithm, kernel design, and optimization, see the paper.
Results
The real test for quantization is reasoning, where errors compound over thousands of tokens. The table below shows Qwen3-4B, where the effect is most dramatic. Look at AIME-24: AWQ drops to 62.2 and EfficientQAT collapses to 45.6, while ParoQuant holds at 73.3, close to the FP16 baseline of 75.6. EfficientQAT fine-tunes weights but lacks a strong transform, showing that outlier suppression is the real bottleneck.
| Method | Type | MMLU | GPQA | AIME24 | AIME25 | Average | Speedup |
|---|---|---|---|---|---|---|---|
| FP16 | – | 71.0 | 50.0 | 75.6 | 62.2 | 64.7 | 1.0× |
| QTIP | vector | 69.7 | 55.2 | 67.8 | 58.9 | 62.9 | 1.5× |
| AWQ | linear | 68.2 | 52.2 | 62.2 | 53.3 | 59.0 | 2.3× |
| EfficientQAT | linear | 67.5 | 49.8 | 45.6 | 44.4 | 51.8 | 2.3× |
| ParoQuant | linear | 70.1 | 53.7 | 73.3 | 63.3 | 65.1 | 2.1× |
The pattern holds across all models we tested (1.7B to 70B), with ParoQuant achieving the best perplexity among linear quantization methods and near-lossless accuracy on non-reasoning benchmarks. Full results for Qwen3-8B, Qwen3-14B, DeepSeek-R1-8B, and detailed throughput breakdowns are in the paper.
Conclusion
ParoQuant shows that you don’t need expensive full rotations to get state-of-the-art quantization. A handful of carefully chosen, independent pairwise rotations, cheap enough to fuse into a single CUDA kernel, match the accuracy of far more complex methods while running at near-AWQ speed.
The payoff is especially large for reasoning LLMs, where every token of chain-of-thought compounds quantization error. ParoQuant keeps that error in check, making 4-bit reasoning models practical without sacrificing the thinking that makes them powerful.
Citation
@inproceedings{liang2026paroquant,
title = {{ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference}},
author = {Liang, Yesheng and Chen, Haisheng and Zhang, Zihan and Han, Song and Liu, Zhijian},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026}
}