 Z Lab
Z LabSparseLoRA: Accelerating LLM Fine-Tuning with Contextual Sparsity
Samir Khaki*, Xiuyu Li*, Junxian Guo*, Ligeng Zhu, Chenfeng Xu, Konstantinos N. Plataniotis, Amir Yazdanbakhsh, Kurt Keutzer, Song Han, Zhijian Liu
LoRA, QLoRA, and DoRA have made LLM fine-tuning accessible by cutting the number of trainable parameters. But they leave a major bottleneck untouched: compute. The frozen base model still runs every computation in every layer, for every token, at every step. QLoRA and DoRA are often slower than plain LoRA because of the overhead they add.
SparseLoRA targets this overlooked bottleneck. By dynamically skipping unnecessary computations in the frozen base layers during training, it achieves up to 2.2× compute reduction and 1.9× wall-clock speedup without sacrificing accuracy.
Quick Start
pip install git+https://github.com/z-lab/sparselora.gitThen add a few lines to any LoRA training script:
from transformers import AutoModelForCausalLM, Trainer
from peft import get_peft_model, LoraConfig
from sparselora import SparseLoRAConfig, apply_sparselora
model = AutoModelForCausalLM.from_pretrained("NousResearch/Meta-Llama-3-8B-Instruct")
model = get_peft_model(model, LoraConfig(r=32, target_modules="all-linear"))
config = SparseLoRAConfig.from_pretrained("z-lab/Meta-Llama-3-8B-Instruct-SparseLoRA", mode="o1")
model = apply_sparselora(model, config)
trainer = Trainer(model=model, ...)
trainer.train()The Real Bottleneck: Frozen Base Layers
Where does the time actually go? Profiling LoRA fine-tuning reveals that the adapters are tiny and fast. The frozen base model, which nobody optimizes, dominates the runtime.
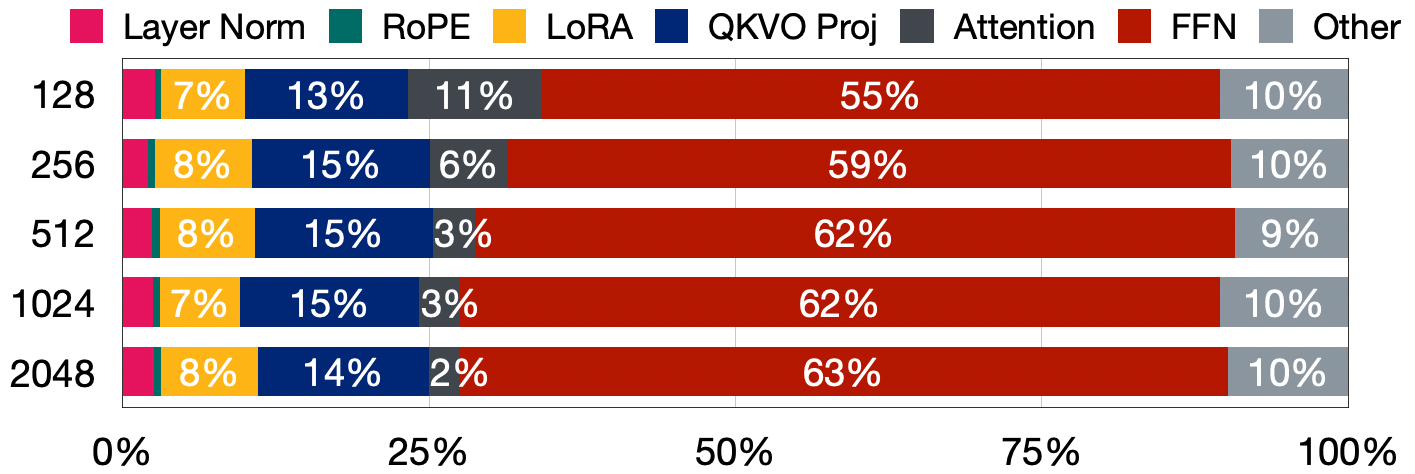
Contextual sparsity has been used to accelerate LLM inference by skipping neurons that contribute little for a given input. But can the same idea work for training? It turns out it can: only a sparse subset of weight channels is needed for loss and gradient computation, and which channels matter depends on the input.
How SparseLoRA Works
The key challenge: figuring out which channels to keep, fast enough that the selection itself doesn’t eat up the savings. Prior approaches train a neural network predictor, but that adds complexity and doesn’t generalize across tasks. SparseLoRA takes a simpler route: an SVD-based sparsity estimator that uses a low-rank decomposition of the frozen weights to approximate channel importance. It’s computed offline, adds less than 1% runtime overhead, and requires no training.
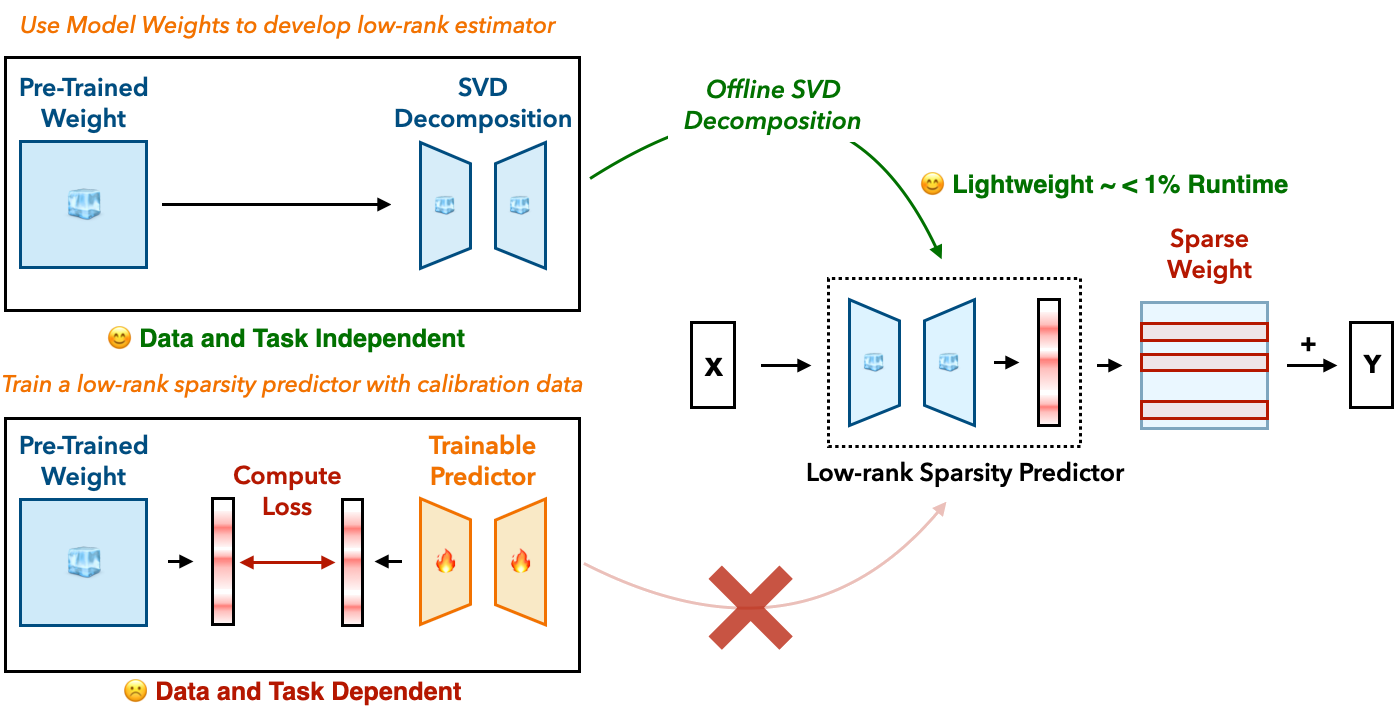
The estimator feeds different pruning criteria depending on the layer type: attention scores for QK projections, activation norms for value/output projections and FFN layers. Sparsity is applied only to the frozen base model, not the LoRA adapters (which are already cheap).
What We Learned About Sparsity
Can you just apply uniform sparsity everywhere? No. Through systematic analysis, we found that sparsity needs to be tuned across three dimensions:
Layers. Deeper layers are more redundant and tolerate aggressive sparsification. Shallow layers are sensitive and should stay dense. Non-uniform per-layer sparsity consistently outperforms uniform sparsity at the same FLOP budget.
Tokens. Output tokens (used for loss computation) are highly sensitive to sparsity. Context tokens are not. SparseLoRA applies sparsity only to context tokens while keeping output tokens dense.
Training steps. Early steps establish gradient flow and are sensitive to approximation errors. SparseLoRA runs dense for the first ~10% of steps, then switches to sparse training for the rest.
Results
The table below shows the end-to-end impact on LLaMA3-8B when applied on top of HuggingFace PEFT. Beyond sparsity, SparseLoRA also patches LoRA’s implementation to reduce overhead from rotary embeddings and residual-adds.
| Method | Forward (ms) | Backward (ms) | Total (ms) | Speedup |
|---|---|---|---|---|
| PEFT LoRA | 714 | 843 | 1558 | 1.0× |
| Optimized LoRA | 623 | 679 | 1302 | 1.2× |
| SparseLoRA | 384 | 436 | 820 | 1.9× |
Across all benchmarks, SparseLoRA maintains accuracy comparable to dense LoRA. The speedups range from 1.3× on commonsense reasoning and code generation up to 1.6× on arithmetic reasoning, with instruction following in between at 1.5×. SparseLoRA also combines naturally with QLoRA for simultaneous memory and compute savings. Full results across LLaMA2-7B/13B and LLaMA3-8B are in the paper.
Conclusion
SparseLoRA shows that contextual sparsity, long explored for inference, translates directly to fine-tuning. By skipping computations on frozen base layers that contribute little to the current input, it provides a practical path to faster training without sacrificing accuracy.
The approach is complementary to existing PEFT methods. LoRA, QLoRA, and DoRA all reduce parameters and memory; SparseLoRA reduces the compute they leave on the table. The key ingredients: a training-free SVD estimator that determines which channels to prune, and a multi-dimensional sparsity policy that determines how much, varying across layers, tokens, and training steps.
Citation
@inproceedings{khaki2025sparselora,
title = {{SparseLoRA: Accelerating LLM Fine-Tuning with Contextual Sparsity}},
author = {Khaki, Samir and Li, Xiuyu and Guo, Junxian and Zhu, Ligeng and Xu, Chenfeng and Plataniotis, Konstantinos N. and Yazdanbakhsh, Amir and Keutzer, Kurt and Han, Song and Liu, Zhijian},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2025}
}